[논문] Early Fire Detection System by Using Automatic Synthetic Dataset Generation Model Based on Digital Twins
Early Fire Detection System by Using Automatic Synthetic Dataset Generation Model Based on Digital Twins
Abstract
- 특정 공간에 최적화된 조기 화재 감지 시스템 제안
- 디지털 트윈 기반의 자동 화재 학습 데이터 생성 모델을 통해 구현
- 현실적인 입자 시뮬레이션을 자동으로 생성하여 RGB-D 이미지 형식의 합성 화재 데이터를 제작하는 것에서 시작
⟶ 이미지들은 실제 공간을 본뜬 디지털 트윈 환경에서, 모니터링 카메라의 시야각과 일치하도록 매칭 ⟶ 각 공간 고유의 다양한 화재 시나리오를 반영한 합성 화재 데이터 생성 ⟶ 생성된 데이터셋을 Transfer Learning에 활용하여 최신 화재 감지 모델의 성능 향상 ⟶ 실제 공간에 배치된 AIoT 디바이스에 모델을 적용 - 공간 맞춤형 합성 화재 데이터 생성 과정은 더 높은 정확도와 낮은 오탐률을 달성
1. Introduction
- 스마트 시티 연구 - 화재 대응 방법에 인공지능 및 IoT 기술과 융합한 방식으로 해결
- 디지털 트윈: 물리 공간에 대한 정보를 디지털 공간으로 전송하여 현실세계를 반영한 쌍둥이가 되는 세계를 디지털 가상 공간에서 재현한 것. 물리적인 공간의 데이터를 수집하는 센서, 현실 세계를 증강시키는 AR, 가상 세계를 구축하는 VR과 같은 기술을 종합적으로 포괄하는 개념
- 기존에 배치된 CCTV를 활용함으로 설치 비용을 최소화, 현재의 화재 상태를 사전에 파악해 오인 출동을 줄임
- 화재 조기 검출을 위해 CCTV와 같은 영상 인식 센서를 활용, 디지털 트윈 기반의 학습 데이터 자동 생성 모델을 활용한 화재 검출 시스템 제안
- RGB-D 카메라를 이용해 현장 CCTV 카메라의 시점과 동일한 RGB-D 영상을 얻고, 파티클 시뮬레이션 기반으로 화재 상황 연출 ⟶ 최적화된 맞춤형 학습 데이터를 대량으로 생성해 화재 조기 검출 인공지능 모델을 학습
2. Materials and Methods
디지털 트윈(Digital Twin, DT): 물리적인 대상과 그에 상응하는 디지털 정보가 상호작용하며 서로 영향을 주고받는 개념
Figure 1
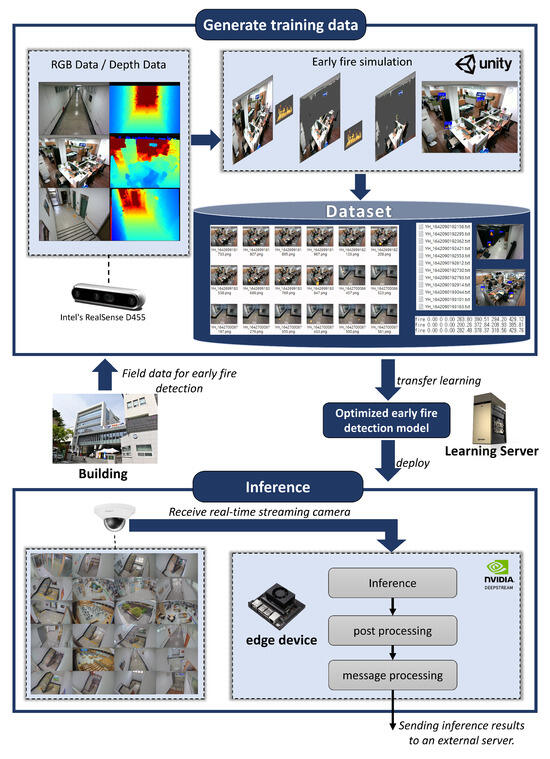
- 실제 이미지 데이터 수집, 가상 화재 발생 합성 이미지 생성, 학습 데이터셋 자동 생성, 화재 조기 감지 모델 전이 학습, AI 장치 추론, 후처리 등의 단계로 구성
2.1. Real Environment Data
가상 데이터 생성: Intel의 RealSense D455 모델 ⟶ 데이터 생성 시 피룡한 RGB 및 Depth 데이터 수집. 촬영 중인 카메라의 각도 정보도 함께 획득해 Unity3D를 활용한 시뮬레이션에서 동일한 구성을 가상 공간에 재현. Intel이 제공하는 RealSense Viewer 툴을 사용해 촬영. RealSense SDK를 이용하면 원하는 프레임 데이터 추출 가능. 다양한 현장에서 실제 이미지 데이터 확보를 위해 조명이 꺼진 상태 등 다양한 환경 변화를 고려하여 촬영
Figure 2
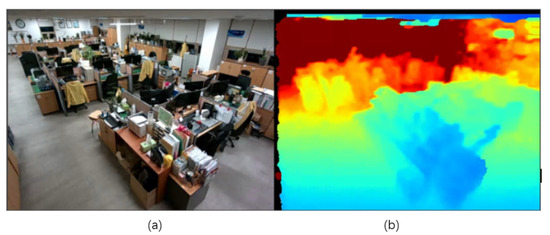
- (a): 실제 사무실
- (b): 사무실 환경에서 CCTV와 동일한 시점을 RealSense로 수집한 Depth 이미지. (깊이가 증가할수록 파란색에서 빨간색)
2.2. Virtual Fire Data
가상 화재를 구현하기 위해 Particle System 사용.
Figure 3

- Unity3D의 파티클 시스템을 사용하여 점차 커지는 가상 화재의 예시
RealSense SDK를 사용하여 실제 환경에서 촬영된 이미지와 Unity 3D의 화재 파티클 시스템과 합성. RealSense SDK의 RGB 및 Depth 데이터를 활용하는 Background Segmentation Shader는 각 구간별 거리만큼의 픽셀을 남기고 나머지를 투명하게 처리 ⟶ 실제 공간의 배경 판별, 가상 공간 내 화재와 가상 카메라 사이의 거리를 측정하고 배경 분할(Backdrop Segmentation) 파라미터를 조정함으로 마치 화재가 실제 공간에 도달한 것 처럼 표현.
Figure 4
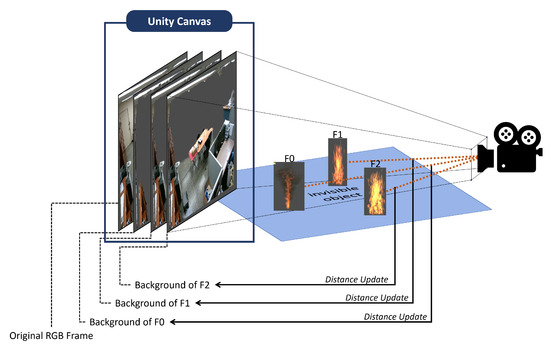
- 실제 환경과 가상 화재의 합성 과정
Unity3D의 캔버스 위에 원본 RGB 프레임을 생성한 후, 카메라로부터 가장 멀리 있는 화재부터 렌더링 ⟶ 각 화재를 순차적으로 그리며 해당 화재와 가상 카메라 사이의 거리 계산 ⟶ 더 먼 거리 값을 가진 모든 픽셀에 대해 배경 분할을 투명하게 수행한 결과를 렌더링하여 화재에 가장 가까운 픽셀만을 남김 ⟶ 모든 화재를 이와 깉이 깊이 정보를 고려하여 그리면, Figure 5와 같이 카메라 시점에서 화재 앞에 있는 객체가 화재를 가리는 자연스러운 상황 재현 가능
Figure 5

- 깊이 정보를 고려한 가상 화재 시뮬레이션 결과
- Figure 6과 같이, 가연 물질의 종류에 따라 다양한 형태를 시뮬레이션하여 여러 유형의 화재를 구현. 화재의 크기는 소형, 중형, 대형으로 구분. 총 35개의 가상 화재 객체가 화재 데이터 생성을 위해 사용됨.
- 사용된 가연 물질: 알코올, 동물, 전기, 섬유, 휘발유, 주방 화재, 램프 오일, 페인트, 플라스틱, 고무, 식물성 기름, 전선 등 포함
Figure 6

- 가연 물질의 종류에 따른 여러 유형의 화재 예시
2.3. Automatic Dataset Generation
- 가상 화재 자동 생성 방식에서 화재가 배치될 때 화재의 위치를 적절히 조정하는 기술 필요
- 가상 카메라 앞에 가상 충돌체 배치. Figure 7a와 같이 해당 스크린 좌표를 기준으로 가상 공간 내에 광선(ray)을 생성하고, Raycast를 실행하여 충돌체와 만나는 지점에 임시로 화재를 배치 ⟶ 화재가 렌더링되는 지점에서 깊이 데이터를 이용해 실제 공간의 거리 값을 읽어오고, 가상 화재와 카메라 사이의 거리를 일정 값 이하가 되도록 조정
Figure 7
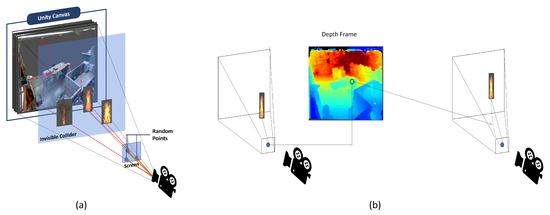
- (a): 화면 상의 임의 좌표를 이용한 화재의 임시 배치
- (b): 가상 화재에 대한 자동 거리 조정
자동 배치된 화재에 화재 시뮬레이션 이미지 추출. 화재 또는 연기의 범위를 지정하기 위해 BoxColider의 좌표(𝑥ₘᵢₙ, 𝑦ₘᵢₙ, 𝑧ₘᵢₙ; 𝑥ₘₐₓ, 𝑦ₘₐₓ, 𝑧ₘₐₓ)를 annotation 정보로 사용 ⟶ 가상 화재를 생성할 때 학습 데이터를 추출하기 위해 BoxColider가 화면상에 형성하는 직육면체 (모든 면이 서로 수직인 기준 벡터를 가지는 axis-aligned bounding box, AABB)를 계산하여 출력.
Figure 8

- (a): annotation 생성을 위한 BoxCollider 설정 예시
- (b): BoxCollider가 그려질 때 모든 꼭짓점을 포함하는 AABB를 파란색으로 나타낸 예시. 화재 이미지에 대해 자동적으로 생성된 annotation 정보
학습 단계에서 활용될 데이터셋은 자동으로 생성된 가상 데이터와 실제 데이터를 병합하여 구축. 실제 화재 데이터는 FireNET에서 제공하는 데이터셋 사용
Figure 9

- FireNET에서 제공한 실제 환경의 화재 학습 데이터
Figure 10

- 사용자 환경에 최적화된 자동 생성 가상 화재 데이터
2.4. Fire Detection Model
- 모델 학습은 NVIDIA TAO Toolkit을 사용하여 수행.
- NVIDIA TAO: Transfer Learning을 위한 사전 학습 모델의 선택, 최적화, 미세 조정 등을 포함하여 딥러닝 모델 구축을 간소화하는 툴킷. Transfer Learning Toolkit(TLT) 포함. Transfer Learning부터 실제 현장에서의 추론을 위한 엣지 AI 디바이스 배포까지의 워크플로우 제공. 다만 지원하는 모델의 제한적이기에 모델 선택에 제약 존재. 본 연구에서는 NVIDIA에서 제공하는 객체 탐지 모델 중 YOLOv4의 Backbone 아키텍처로 ResNet18 선택.
- 전이 학습(Transfer Learning): 이미 학습된 모델의 가중치와 구조를 가져와 새로운 작업에 맞춰 조금만 추가 학습(fine-tuning)하는 기술
- NVIDIA TAO: Transfer Learning을 위한 사전 학습 모델의 선택, 최적화, 미세 조정 등을 포함하여 딥러닝 모델 구축을 간소화하는 툴킷. Transfer Learning Toolkit(TLT) 포함. Transfer Learning부터 실제 현장에서의 추론을 위한 엣지 AI 디바이스 배포까지의 워크플로우 제공. 다만 지원하는 모델의 제한적이기에 모델 선택에 제약 존재. 본 연구에서는 NVIDIA에서 제공하는 객체 탐지 모델 중 YOLOv4의 Backbone 아키텍처로 ResNet18 선택.
Figure 11
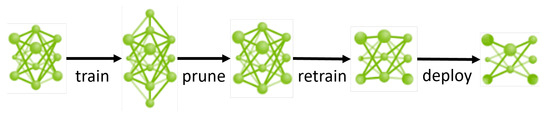
- NVIDIA TAO에서의 전이 학습 및 모델 베포 과정
- Train: 사전 학습된 모델을 가져와, 새로운 데이터(가상 + 실제 화제 데이터 등)로 학습 시작
- Prune(가지치기): 불필요한 뉴런이나 연결(가중치가 거의 없는)을 제거하여 모델을 경량화
- 속도 향상 및 메모리 절약
- Retrain: 가지치기 후 다시 학습하여 성능 보완
- Deploy: 최종적으로 경량화된 모델을 엣지 디바이스(데이터를 클라우드나 중앙 서버로 보내지 않고, 장치 자체에서 실시간으로 처리할 수 있는 장치)나 실제 운영 환경에 배포
- NVIDIA TAO에서의 전이 학습 및 모델 베포 과정
전이 학습은 사전 학습된 모델을 활용하여 수행, 학습이 완료된 후에는 파라미터 수를 줄이기 위한 가지치기 과정을 거쳐 한 번 더 학습을 진행. 이후 모델은 엣지 디바이스 배포를 위해 암호화된 형태로 변환. 모델 변환 과정은 추론 단계에서 사용되는 DeepStream 활용.
Figure 12

- 바운딩 박스 표시 임계값(객체 탐지 모델이 예측한 신뢰도가 특정 임계값 이상일 때만 바운딩 박스를 시각적으로 표시하는 기준)을 0.6으로 설정하여 테스트 데이터를 추론한 결과
2.5. AI Inference and Post-Processing
- 가상 데이터를 학습한 현장 최적화 모델은 각 현장에 배치된 AI 디바이스를 통해 추론 수행. NVIDIA TAO와 연동 가능한 디바이스에는 NVIDIA Jetson의 Xavier 시리즈와 Orin 시리즈가 있으며, 본 연구에서는 Jetson Xavier NX를 사용
- DeepStream: 딥러닝 기반 추론 과정을 가속화할 수 있는 GStreamer 기반의 플러그인 및 라이브러리
- Transfer Learning Toolkit(TLT)을 통해 학습된 모델은 DeepStream 환경에서 배포 가능.
- 내부적으로 TensorRT 추론 엔진 사용 ⟶ TAO에서 배포된 암호화된 모델 파일은 TAO Converter를 이용해 TensorRT용 엔진 파일로 변환
- DeepStream 애플리케이션에서 GStreamer 파이프라인 구성 ⟶ 입력 영상(CCTV 등)의 디코딩부터 실험 현장에서 발생 가능한 문제를 해결하기 위한 후처리(post-processing) ⟶ 최종 화재 감지 결과를 화면 표시(OSD)를 통해 외부로 전송하는 과정까지 수행
- 추론 결과 혹은 영상은 외부 데이터로 전송 가능, 본 연구에서는 외부 Kafka 서버를 구축하여 화재 감지 정보를 Kafka 메시지로 전송
Figure 13
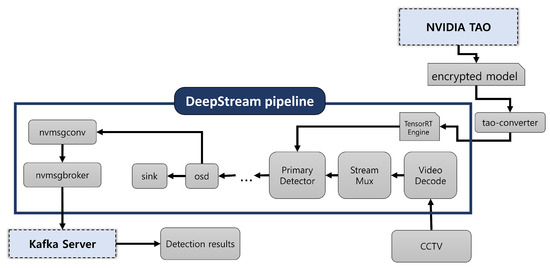
- TAO에서 배포된 모델을 DeepStream에서 활용하여 추론 및 후처리를 수행하는 과정, Kafka 메시지로 결과 데이터가 전달되는 전체 과정
화재 감지 정보를 포함한 메시지는 Figure 14와 같이 구성. 감지된 객체(화재)에 대해 화재 또는 연기를 구분하는 classID, 감지된 위치를 나타내는 바운딩 박스(rectangle), 해당 감지에 대한 모델의 신뢰도(confidence score)가 포함되며, 엣지 디바이스의 ID 값이 메타데이터로 첨부됨
Figure 14
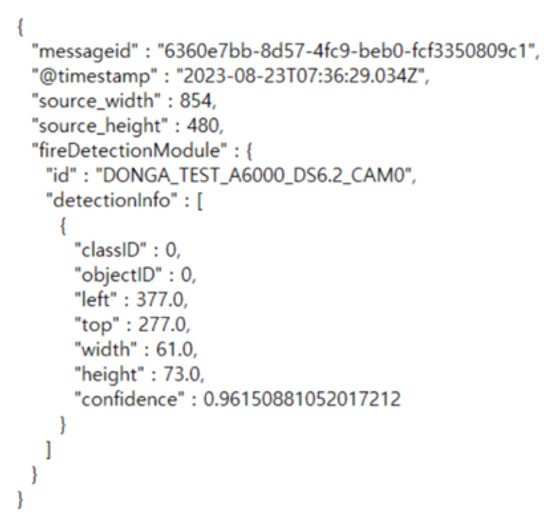
- DeepStream에서 전송한 감지 결과에 대한 메시지
- 화재 추적을 위한 후처리(post-processing) 기법: 추적된 화재의 첫 번째 바운딩 박스의 대각선 길이와 이후 바운딩 박스들의 대각선 길이 간의 창 저장, 최근 15개의 차이값으로부터 누적값(\(d_{cummulative}\))계산, 특정 임계값과 비교하여 화재의 움직임 여부 확인
- \(d_{cummulative}\): 화재 크기(또는 위치)변화의 누적량.
- \[d_t = \left| \mathbf{p}_{0_{RB}} - \mathbf{p}_{0_{LT}} \right| - \left| \mathbf{p}_{t_{RB}} - \mathbf{p}_{t_{LT}} \right| ;\quad d_{\text{cumulative}} = \sqrt{ \sum_{t=1}^{n} (d_0 - d_t)^2 }\]
- \(p_{RB}\), \(p_{LT}\)는 각각 바운딩 박스의 Right-Bottom, Left-Top 꼭짓점 의미
- \(d_t\): \(t\) 시점에서의 바운딩 박스 대각선 길이의 변화량
- \(d_{cummulative}\): 기준 시점 \(t=0\)에서의 길이와 현재까지의 변화량을 누적해 제곱 평균 제곱근(RMSE) 형태로 계산한 값
- Figure 15와 같이, 추적된 화재의 첫 번째 바운딩 박스 중심에서, 첫 번째 바운딩 박스의 좌상단까지의 벡터 \(\vec{v}_{0_{LT}}\)와, \(t\)번째 바운딩 박스의 좌상단까지의 벡터 \(\vec{v}_{t_{LT}}\) 사이의 각도 \(\theta_{t_{LT}}\)의 코사인 값을 계산하고, 해당 값이 특정 임계값 내에 있는지 확인하여 화재 여부 검증.
- 실험 결과, 화재 여부를 판단하는 데 가장 적절한 코사인 유사도 임계값은 0.9-0.98 범위
- \[\cos{\theta_{t_{LT}}} = \frac{\vec{v}_{0_{LT}} \cdot \vec{v}_{t_{LT}}}{|\vec{v}_{0_{LT}}||\vec{v}_{t_{LT}}|} \quad ; \quad \cos{\theta_{t_{RB}}} = \frac{\vec{v}_{0_{RB}} \cdot \vec{v}_{t_{RB}}}{|\vec{v}_{0_{RB}}||\vec{v}_{t_{RB}}|}\]
- 두 벡터 간의 방향이 얼마나 유사한지 나타내는, Cosine Similarity(코사인 유사도)를 구하는 공식
- \(\theta_{t_{LT}}\): 첫 번째 프레임과 \(t\)번째 프레임의 좌상단 벡터 간의 각도
- \(\theta_{t_{RB}}\): 우하단 벡터 간의 각도
Figure 15
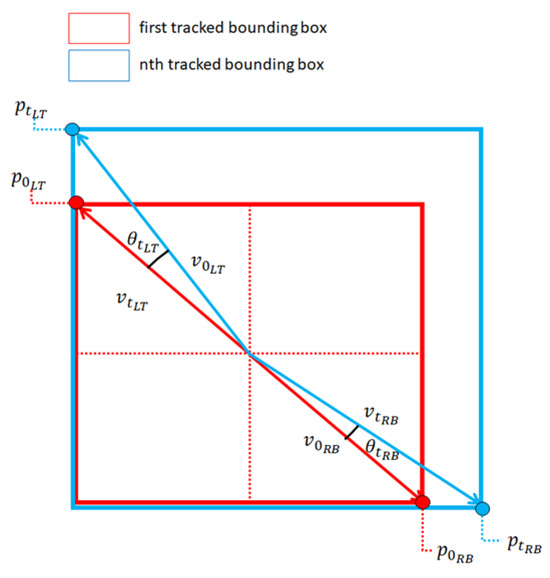
- 화재 추적을 위한 두 바운딩 박스 분석
3. Experimental Results
3.1. IoT Installation
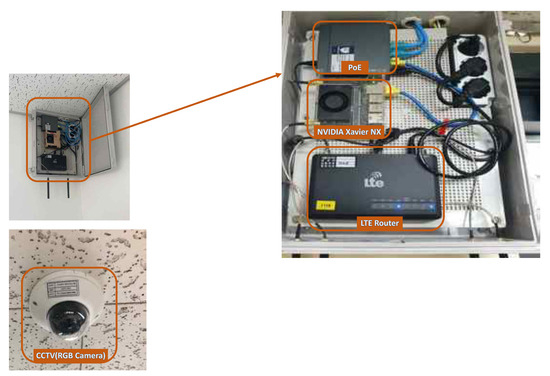
실시간 영상 소스를 수집하기 위한 CCTV, 인터넷 연결을 위한 라우터, 화재 감지 애플리케이션을 실행할 NVIDIA Xavier NX로 구성된 유닛을 조립하여 엣지 추론. 이 유닛은 CCTV가 설치된 벽 상단에 부착.
Figure 16
3.2. Virtual Fire Data
Figure 17
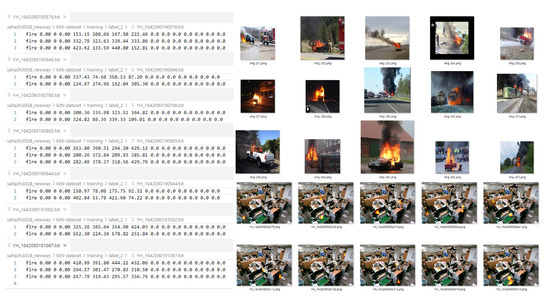
- 초기 화재 및 다양한 화재 유형을 포함하는 가상 이미지와 실제 이미지로 구성된 학습 데이터셋
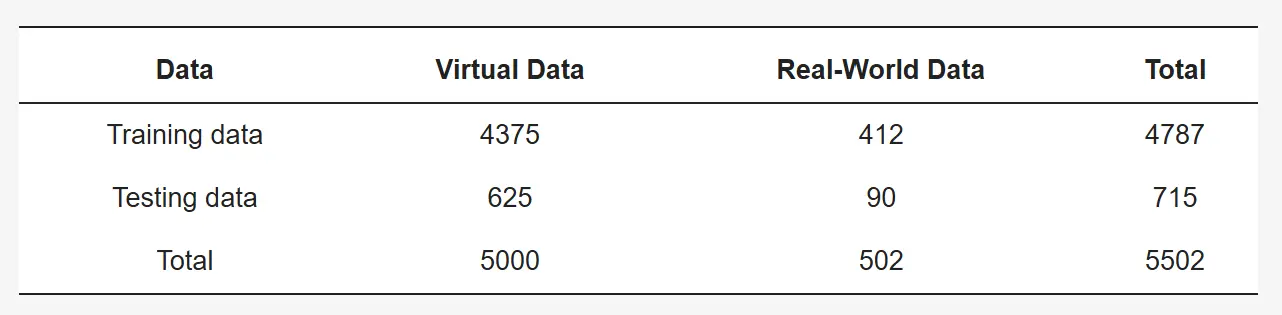
가상 화재 데이터를 생성하기 위한 실제 환경으로 43개의 실내 장소에서 조명이 켜진 상태와 꺼진 상태 모두에서 RGB 및 Depth 데이터를 기록. 각 장소별로 7,000개의 가상 불꽃 입자 데이터와 7,000개의 가상 연기 입자 데이터를 생성하여 장소당 총 14,000장의 이미지를 만들었으며, 전체적으로 약 60만 개의 가상 화재 데이터를 생성
Figure 18

- 다양한 실제 세계 환경에서 만들어진 가상 화재 데이터
본 연구의 목적은 특정 실제 장소에서 발생하는 작은 초기 화재를 신속하게 탐지하는 것. 이를 위해 각 장소에 맞춘 가상 데이터와 해당 장소와 무관한 실제 데이터를 결합하여, 해당 장소에 최적화된 모델 도출
Table 1: Number of training images for a single specific environment.
3.3. Results
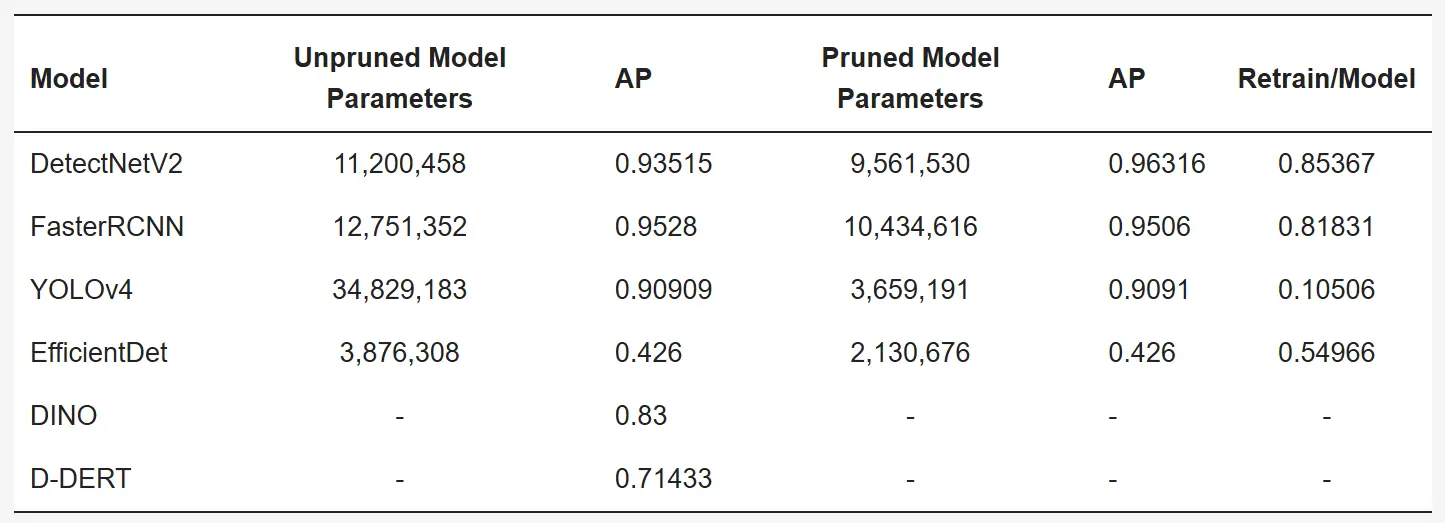
학습 단계에서는 NVIDIA의 DGX A100이 학습 환경으로 사용됨. NVIDIA TAO에서 제공하는 Object Detection 모델인 DetectNet_v2, FastRCNN, YOLOv4, EfficientDet, DINO를 개발하고 학습. 모든 학습 모델에 대해 테스트 세트를 사용하여 평가한 결과는 Talbe 2에 제시.
Figure 19: The NVIDIA DGX A100, which was used as a training environment.

Table 2: The final evaluation results of the trained model.
현장 최적화 측면에서 학습에 사용되지 않은 새로운 데이터를 추론하기 위해 화재 입자를 활용하여 가상 데이터 생성. 기존 형태의 화재 입자를 사용할 경우 어떤 모델을 사용하더라도 confidence가 0.95 이상으로 문제 없이 탐지되었고, 오탐지(false detection)도 발생하지 않음 ⟶ Figure 20
Figure 20
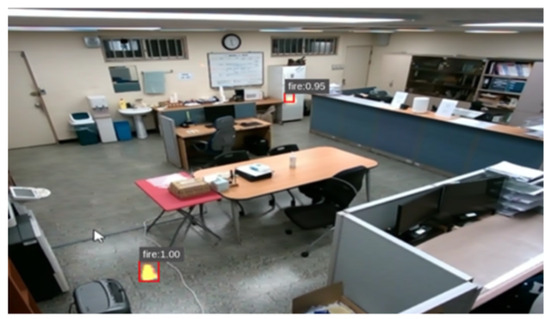
- 학습 데이터 생성을 위해 사용된 화재로부터 새로운 화재 영상 추론
사용하지 않은 형태의 다른 화재 입자를 이용해 화재 이미지를 생성한 경우 높은 탐지율을 보였지만, 일부 오탐지 결과 존재 ⟶ Figure 21
Figure 21

- 모든 모델의 성능 지표는 높게 나타남
높은 성능 평가 점수와 달리 일부 모델은 일반적인 화재 영상에 대해 추론하지 못하거나 오탐지
Figure 22: YOLOv4 model correctly inferred small fires (a) and the DetectNetV2 model did not (b).

Figure 23: YOLOv4 model does not make false detections for dark environments other than fire (a) and DetectNetV2 model detects dark areas as smoke (b).

YOLOv4 모델이 초기 화재를 가장 적은 수의 오탐지로 탐지. 이후 YOLOv4 모델의 backbone인 resnet18 대신 resnet50, resnet101, cspdarknet19를 활용하여 학습 진행
Table 3: Evaluation of the detection model according to the backbone of the YOLOv4 model.
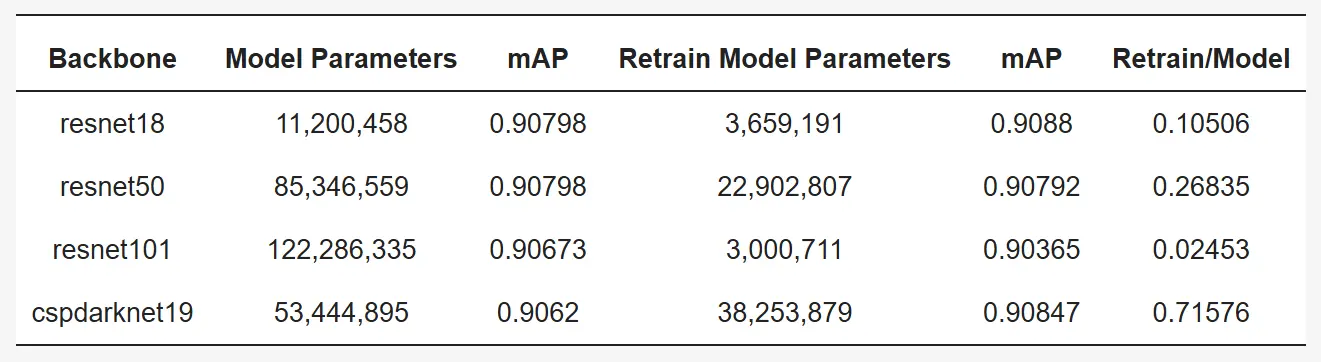
- backbone이 달라졌을 때의 성능 평가 변화
- backbone: YOLOv4 모델에서 사용된 backbone 네트워크(특징 추출기)
- Model Parameters: 학습 전 원래 모델의 전체 파라미터 수
- mAP: 학습 전 모델의 평균 정밀도(mean Average Precision), 객체 탐지 성능 지표
- Retrain Model Parameters: 가지치기 후 재학습된 모델의 파라미터 수
- mAP: 재학습된 모델의 평균 정밀도
- Retrain/Model: 전체 파라미터 수 대비 재학습 모델의 파라미터 비율(작을수록 모델 경량화)
resnet의 경우 층 수가 18에서 101로 증가함에 따라 사전 학습된 모델의 크기가 크게 커지지만, 가지치기 과정을 거친 후에는 오히려 resnet101이 다른 backbone보다 더 적은 수의 파라미터를 가짐. 가지치기 과정은 성능을 유지하면서도 불필요한 파라미터를 줄여 엣지 디바이스에서의 추론에 적합하도록 모델을 최적화.
Figure 24

- 실세계 화재 추론은 YOLOv4 모델의 backbone(기반 신경망 구조)에 따라 달라짐
- Figure 24에서 볼 수 있듯이 resnet50과 cspdarknet19는 화재 초기에 잘 감지되지만 오탐지가 자주 발생되는 반면, resnet101은 오탐지는 거의 없었지만 작은 초기 화재를 빠르게 감지하지 못함. resnet18의 경우 화재의 초기 상태를 잘 감지했으며 오탐률도 매우 낮음
아주 작은 화재에 대해 테스트 진행 ⟶ Figure 25
Figure 25

- 카메라로부터 약 35m 떨어진 지점에서 작은 불씨를 방출해 생성된 약 20x20 픽셀 크기의 불꽃 이미지를 resnet18을 backbone으로 하는 모델이 추론한 결과
3.4. Post-Processing
YOLOv4+resnet18 모델을 사용하더라도 오탐지를 완전히 제거하는 것은 불가능. 단순히 색상만으로 인한 오탐지(Figure 26)가 발생했으며, 이를 위해 화재의 시간적 특성을 검사하는 후처리 과정 추가
Figure 26: Examples of false positives in YOLOv4+resnet18 model inference.

deepstream 파이프라인의 추론 요소 중 nvTracker 요소는 모델이 추론한 화재 객체 추적 ⟶ 추적된 화재의 이전 프레임들에서 탐지된 바운딩 박스의 크기나 형태 변화 계산 ⟶ 일정 기준을 초과할 경우 불꽃의 특성으로 판탄 ⟶ 비화재 객체가 최종적으로 화재로 탐지되는 경우 제거
Figure 27: Inference results after post-processing.

- 실제 화재와 화재와 유사한 색상을 가진 물체에 대한 판별 차이
- 파란색 바운딩 박스: 후처리 이후 최종적으로 화재로 판단된 객체
- 빨간색 바운딩 박스: 후처리 단계에서 불꽃으로 의심은 되었지만, 실제로는 움직임이나 형태 면에서 불꽃의 특성을 보이지 않아 화재로 판별되지 않은 객체
후처리 이후에도 실제 화재에 대한 탐지 성능에 영향을 주지 않음
Figure 28: Correctly inferring a very small fire in the initial state, even after post-processing is added.

4. Conclusions
- 본 연구에서는 화재 조기 감지를 위한 디지털 트윈 기반 현장 최적 학습 데이터 자동 생성 모델 제안.
- 현장에서의 작은 초기 화재도 매우 높은 신뢰도로 탐지, 가상 화재 합성 데이터를 기반으로 한 화재 탐지 모델이 초기 화재를 빠르게 탐지하는 데 큰 가능성을 지님을 검증
- 한계점
- 가상 화재는 불이 배경에 반사되거나, 배경 요소가 불에 타서 재로 변하는 등의 세밀한 묘사까지는 구현하지 않음. 다만 화재 탐지를 위한 데이터에는 큰 영향을 미치지 않을 수 있음
- 실제 현장에서 발생할 수 있는 다양한 시나리오를 충분히 반영한 영상 데이터 수집 중요
- 카메라가 이동하는 상황 고려. 화재 탐지 상황에 따라 시야 및 각도 조절 ⟶ 추가적인 연구와 실험 필요
- NVIDIA TAO 플랫폼은 지원하는 모델이 제한적. 향후 YOLOv8 등 최신 비전 모델을 테스트
- 궁극적으로 본 연구는 조기 화재 감지를 핵심 기술로 삼아, 화재 대피를 위한 정교한 디지털 트윈 시스템을 구축하는 데 중추적인 역할
Presentation